
a Recent Jama articles Only 5% of studies assessing the use of healthcare in large language models (LLM) reported that electronic health records (EHR) data was used. The majority of the reported research findings are based on one of the patient data called Medical Information MART for the Intensive Care (MIMIC) database. Physionetor depends on private data.
MIMIC has been transformative in healthcare AI research, but there is a lack of longitudinal health data. This results in poor imitation to assess LLMS for tasks that require a long-term trajectory of patient care, such as chronic disease management, multivisit prediction, or optimization of care pathways. As a result, there is a gap between the benefits of LLMS and the researcher's ability to examine those benefits in real-life settings. This assessment gap limits the ability to test model generalization across diverse patient populations and healthcare systems, and can only be bridged by introducing EHR benchmarks beyond MIMIC.
Benchmark datasets that reflect the diversity and complexity of real-world healthcare are important to promote fair and scalable AI systems. Simply put, honest assessments of responsible AI and clinical benefits require new benchmarks that include longitudinal patient data and address population representation gaps. This need for new datasets is It is widely recognizedclinical data complexity, strict privacy, and ethical considerations create barriers to data sharing as sharing is not feasible on platforms such as faces hosting many general purpose machine learning benchmarks.
To address this need, we developed three identified EHR benchmark datasets. ehrshot, I'll inspect itand Medalig -As a first step in addressing this “assessment gap.” These datasets represent important advances in enabling rigorous assessment of healthcare AI, making them freely available to researchers around the world for non-commercial use. These datasets complement the release of 20 EHR basic models, including decoder-only transformers (clmbr), event model from event (motor), and Pre-protected weight For benchmarking long contest architectures of subquadratis such as hyenas and mamba.
Taken together, these datasets and models are concrete steps towards a shared vision of robust and accessible tools for the healthcare AI research community.
Summary of identified datasets
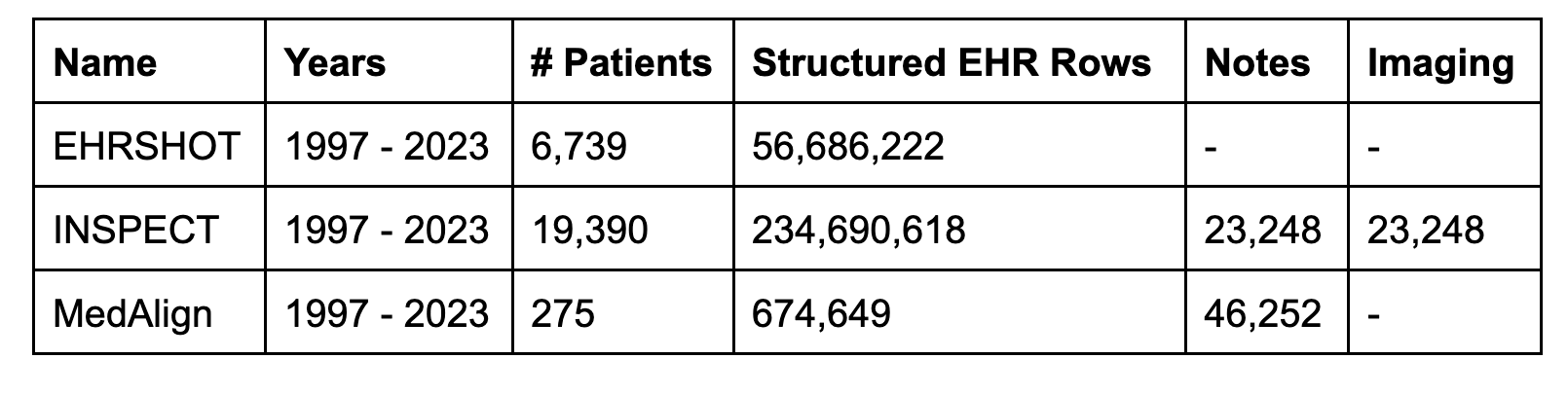
It is grouped into three identified vertical EHR datasets 25,991 unique patients, 441,680 visitsand 295 million clinical events. Although smaller in terms of patient count than mimetic datasets, the dataset provides longitudinal data and provides a detailed view of each patient's health journey. Therefore, it complements the mimic dataset.
Longitudinal data addresses issues of missing contexts
The EHR includes not only unstructured data such as clinical narratives and medical imaging, but also structured information such as lab values and billing codes to provide an overall perspective on patient health. Masu. For example, Inspect Dataset includes 23,248 pairs of CT scans and radiology impressions. MedAlign provides 46,252 clinical notes ranging from 128 different memo types, providing a detailed longitudinal view of patient care across 275 individuals. MedAlign stands out by capturing a variety of contexts that are often missing in other data sets, including such a comprehensive set of clinical documents.
Longitudinal datasets address There's no context issue In medical AI, current medical datasets do not reflect the complete scope of past and future health information for real-world EHRs. Providing such a longitudinal health situation is essential for training multimodal models to understand complex, long-term health patterns, such as chronic disease management and cancer treatment planning.
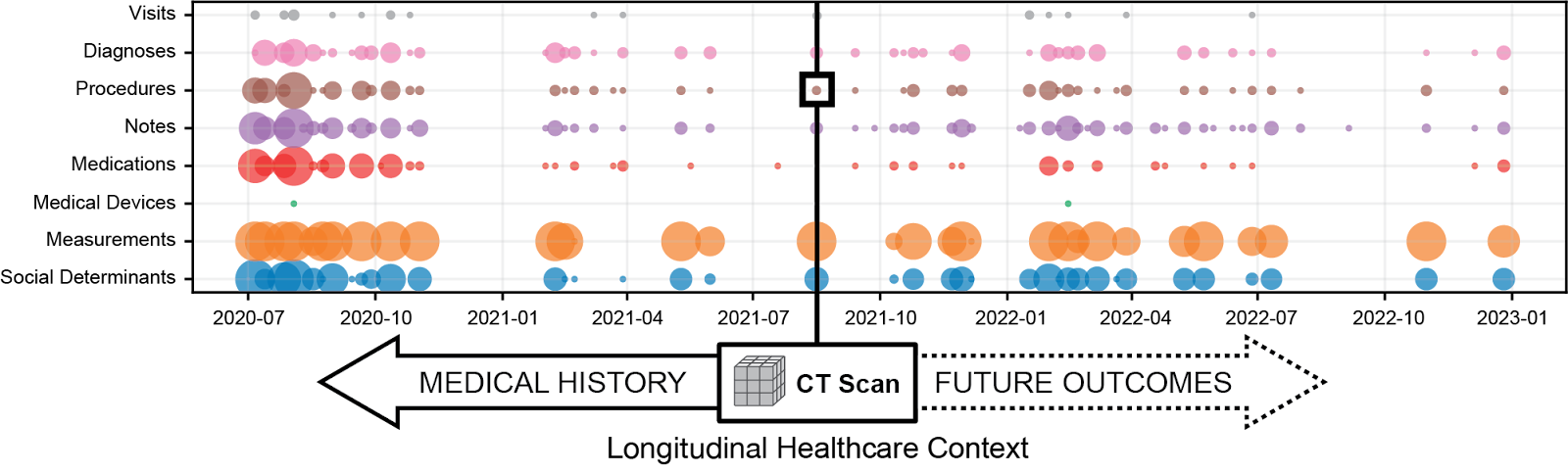
Figure 1. Inspect Dataset's CT scan highlights the important issues of pre-forming visual language model styles. It excludes contexts such as past medical history and future health outcomes. this There's no context issue It limits the ability to train models that incorporate perfect health trajectories (i.e. past and future events) to learn the correlations essential to identify prognostic markers in multimodal data. Adapted diagram from (Huo etal. 2024).
Standardized tasks allow for accurate comparisons
All identified datasets include benchmark tasks to assess current technical challenges affecting healthcare AI. These benchmarking tasks allow for the creation of unified leaderboards and support community tracking for cutting-edge model development.
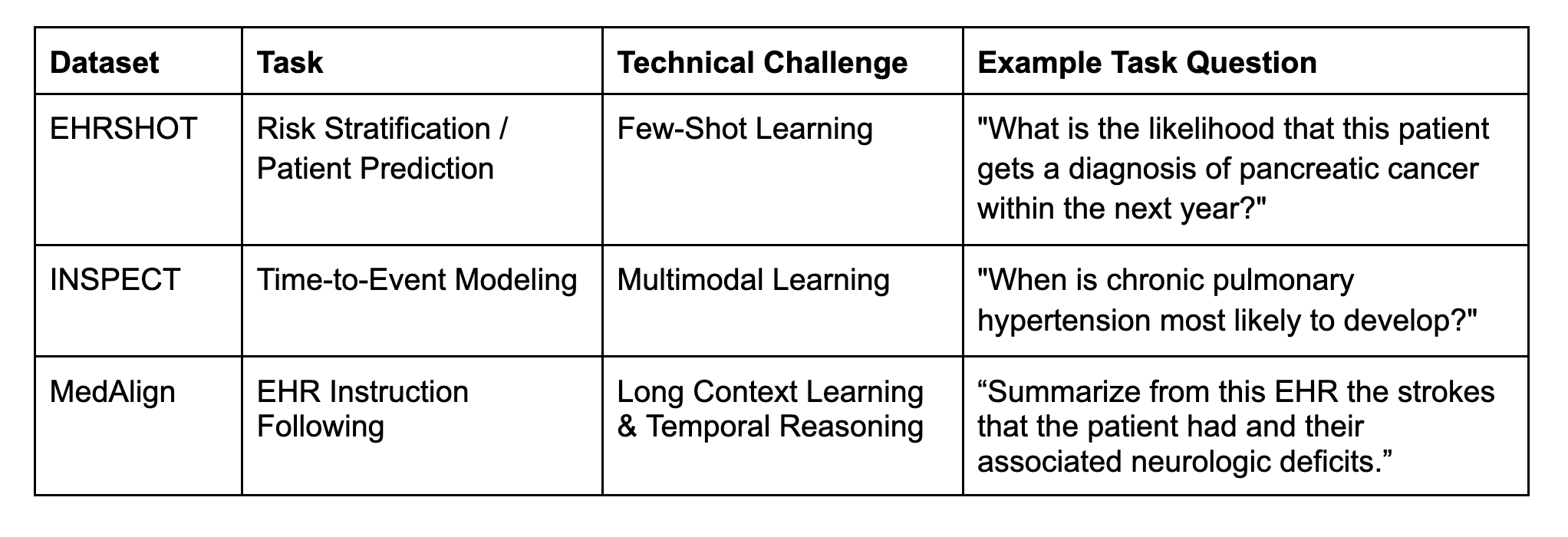
In addition to defining task labels, it is essential to store an invisible holding set of tests to accurately compare the performance of EHR underlying models in classification and prediction tasks. With mimicking data, individual researchers usually define their own train/test splits. This requires retraining a basic model from scratch from scratch, a costly and impractical process that hinders the reproducibility and standardization of performance estimates.
To address this, the benchmark dataset also includes standard train/verification/test divisions across all datasets. These identifiers are consistent across current and future dataset releases. All released EHR foundation models respect this standard split and ensure that benchmark assessments are not plagued by pre-training data leaks.
Compliance with data standards to support the tool ecosystem
Our identified datasets are derived from within Stanford Star Data repository and release Observational Medical Outcome Partnership Common Data Model (OMOP CDM 5.4) format. OMOP supports a robust ecosystem of statistical analysis tools, but is not optimized for training and evaluation of basic models. Therefore, we participated in joint development. Medical Event Data Standard (MEDS)international cooperation between academic institutions such as Harvard University, Massachusetts Institute of Technology (MIT), Columbia University, and the Korea Institute of Advanced Science and Technology (KAIST). , data quality tools, and open source training infrastructure. To bridge the world of OMOP and Meds, Meds Reader To accelerate data loading speed by up to 100 times and make data sets available in MEDS format.
Data Access Protocol and Researcher Responsibility
Although data is obsolete, these are healthcare-related data that must only be accessed through certain access protocols. Data Access Protocol and License are modeled on Physionet, and mimicking datasets serve as important inspiration for approaches to dataset release. Researchers must apply via data portal revissign contracts (DUA) and rules of conduct agreements using user-level data and provide valid CITI training certificates before access to the data is enabled.
The road ahead
We look forward to the community using and building these datasets. As an example, our future Factehr data setthe de facto decomposition and verification benchmarks are constructed using clinical notes sampled from Mimic and Medalign.
More resources
Special thanks
Releasing these datasets was a massive collaboration that included multiple offices and champions across Stanford University and Stanford Healthcare.
This study includes live data from STANFORD Health Care, The Stanford Children's Hospital, University Healthcare Alliance, and Packard Children's Health Alliance Clinics. Data or services provided by the Stanford Medicine Research Data Repository, a clinical data warehouse, was used. From hospital use such as radiation PAC. The Starr platform is developed and operated by the Stanford Medical Research and Technology Team and is now possible with funding from the office of Stanford University's Secretary of Medicine.
Governance, Privacy, License
Austin Aker, Scott Edmiston, Jonathan Goltatt, Marico Kelly, Julie Marie Romero, Reed Sprague
Technology and digital solutions
Somaly Datta, Priya Desai, Todd Ferris, Natasha Flowers, Joseph Mesterhazy
Stanford I-Me Center
Stephanie Bogdan, Sara Bogdan Warner, Johanna Kim, Natalie Lee, Lindsay Park, Angela Singh, Angela Singh, Jacqueline Thomas, Liberty Walton, Gabriel Yip
Stanford Center for Population Health Sciences, Stanford Library, Ladyvis
the study