
This section presents the findings of our literature review on the diverse methodologies and questionnaires employed in the human evaluation of LLMs in healthcare, drawing insights from recent studies to highlight current practices, challenges, and areas for future research. Supplementary Fig. 1 shows the distribution of the LLMs experimented as reported in these reviewed studies.
Healthcare applications of LLMs
Figure 1 illustrates the distribution of healthcare applications for LLMs that underwent human evaluation, providing insights into the diverse range of healthcare domains where these models are being utilized. Clinical Decision Support (CDS) emerges as the most prevalent application, accounting for 28.1% of the categorized tasks. This is followed by medical education and examination at 24.8%, Patient education at 19.6%, and medical question answering at 15.0%. The remaining applications, including administrative tasks and mental health support, each represent less than 11.8% of the total. This distribution highlights the focus of researchers and healthcare professionals on leveraging LLMs to enhance decision-making, improve patient care, and facilitate education and communication in various medical specialties..
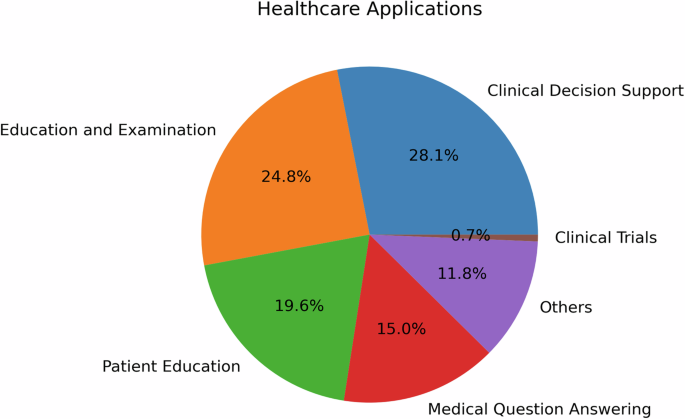
The reviewed studies showcased a diverse range of healthcare applications for LLMs from bench to bedside and beyond, each aiming to enhance different aspects of patient care and clinical practice, biomedical and health sciences research, and education.
As illustrated in Fig. 1, CDS was the most prevalent application, accounting for 28.1% of the categorized tasks. Studies such as Lechien et al.21 and Seth et al.22 provide illustrative examples of how LLMs can improve accuracy and reliability in real-time patient monitoring and diagnosis, respectively. In Lechien et al., forty clinical cases, i.e., medical history and clinical examination of patients consulting at the Otolaryngology-Head and Neck Surgery department, are submitted to ChatGPT for differential diagnosis, management, and treatment suggestions. Expert evaluators rated ChatGPT performance with the Ottawa Clinic Assessment Tool and assessed that ChatGPT’s primary diagnoses and other differential diagnoses are plausible in 90% of the cases and argued it can be “a promising adjunctive tool in laryngology and head and neck surgery practice”. In Seth et al., six questions regarding the diagnosis and management of Carpal Tunnel Syndrome (CTS) are posed to ChatGPT to simulate patient-physician consultation and the author suggested the response have the quality of providing “validated medical information on CTS to non-medical individuals”22. Milliard et al. scrutinized the efficacy of ChatGPT-generated answers for the management of bloodstream infection, setting up comparisons against the plan suggested by infectious disease consultants based on literature and guidelines23. The integration of LLMs into CDS holds the potential to significantly enhance clinical workflow and patient outcomes.
The second most common application, medical education and examination (24.8%), was explored by researchers like Yaneva et al.24, Wu et al.25, and Ghosh et al.26. Yaneva et al.24 evaluated the performance of LLMs on medical licensing examinations, such as the United States Medical Licensing Examination(USMLE), suggesting their potential in medical education. Ghosh et al.26 took this a step further, demonstrating through statistical analysis that LLMs can address higher-order problems related to medical biochemistry.
Patient education, the third most prevalent application (19.6%), was investigated by studies such as Choi et al.27, in which they assessed ChatGPT as a self-learning tool in pharmacology, and Kavadella et al.28, in which they assessed ChatGPT for undergraduate dental education. In addition, Baglivo et al. conducted a feasibility study and evaluated the use of AI Chatbots in providing complex medical answers related to vaccinations and offering valuable educational support, even outperforming medical students in both direct and scenario-based question-answering tasks29. Alapati et al. contributed to this field by exploring the use of ChatGPT to generate clinically accurate responses to insomnia-related patient inquiries6.
Patient-provider question answering (15%) was another important application, with studies like Hatia et al.30 and Ayers et al.3 taking the lead. Hatia et al. analyzed the performance of ChatGPT in delivering accurate orthopedic information for patients, thus proposing it as a replacement for informed consent31. Ayers et al. conducted a comparative study, employing qualitative and quantitative methods to enhance our understanding of LLM effectiveness in generating accurate and empathetic responses to patient questions posed in an online forum3.
In the field of translational research, Peng et al.32 and Xie et al.33 provide insightful contributions. Peng et al. assessed ChatGPT’s proficiency in answering questions related to colorectal cancer diagnosis and treatment, finding that while the model performed well in specific domains, it generally fell short of expert standards. Xie et al. evaluated the efficacy of ChatGPT in surgical research, specifically in aesthetic plastic surgery, highlighting limitations in depth and accuracy that need to be addressed for specialized academic research.
The studies by Tang et al.34, Moramarco et al.35, Bernstein et al.36, and Hirosawa et al.37 underscore the expanding role of LLMs in medical evidence compilation, diagnostic proposals, and clinical determinations. Tang et al. employed a t-test to counterbalance the correctness of medical evidence compiled by ChatGPT against that of healthcare practitioners. Moramarco et al. used chi-square examinations to detect differences in the ease and clarity of patient-oriented clinical records crafted by LLMs. Bernstein et al. enlisted the McNemar test to track down precision and dependability in diagnostic suggestions from LLMs and ophthalmologists. Hirosawa et al. carried out a comparison between LLM diagnoses and gold-standard doctor diagnoses, targeting differential diagnosis accuracy.
Medical specialties
To ensure a thorough analysis of medical specialties, we have adopted the classifications defined by the 24 certifying boards of the American Board of Medical Specialties38. Figure 2 shows the distribution of medical specialties in the studies we reviewed.
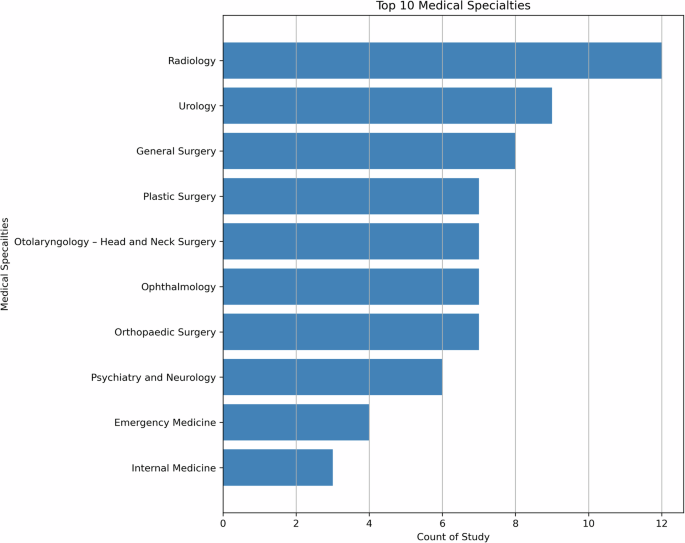
The literature review revealed a diverse range of medical specialties leveraging LLMs, with Radiology the leading specialty. Urology and General Surgery also emerged as prominent specialties, along with Plastic Surgery, Otolaryngology, Ophthalmology, Orthopedic Surgery and Psychiatry, while other specialties had fewer than 5 articles each. This distribution highlights the broad interest and exploration of LLMs across various medical domains, indicating the potential for transformative impacts in multiple areas of healthcare, and the need for comprehensive human evaluation in these areas.
As illustrated in Fig. 2, the literature review revealed a diverse range of medical specialties leveraging LLMs, with Radiology leading (n = 12). Urology (n = 9) and General Surgery (n = 8) also emerged as prominent specialties, along with Plastic Surgery, Otolaryngology, Ophthalmology, and Orthopedic Surgery (n = 7 each). Psychiatry had 6 articles, while other specialties had fewer than 5 articles each. This distribution highlights the broad interest and exploration of LLMs across various medical domains, indicating the potential for transformative impacts in multiple areas of healthcare, and the need for comprehensive human evaluation in these areas.
In Radiology, human evaluation plays a crucial role in assessing the quality and accuracy of generated reports. Human evaluation in Radiology also extends to assessing the clinical utility and interpretability of LLM outputs, ensuring they align with radiology practices39. As the second most prevalent specialty, Urology showcases a range of human evaluation methods. Most evaluate methods are applied in patient-centric applications, such as patient education and disease management, which often utilize user satisfaction surveys, feedback forms, and usability assessments to gauge the effectiveness of LLM-based interventions. In the General Surgery specialty, human evaluation focuses on the practical application of LLMs in pre-operative planning, surgical simulations, and post-operative care. Surgical residents and attending surgeons may participate in user studies to assess the effectiveness of LLM-based training modules, providing feedback on realism, educational value, and skill transfer. Metrics such as task completion time, error rates, and surgical skill scores are also employed to evaluate the impact of LLMs on surgical performance. In Plastic Surgery and Otolaryngology specialties, human evaluation often revolves around patient satisfaction and aesthetic outcome, for instance, to gather feedback on LLM-assisted cosmetic and reconstructive surgery planning.
In Emergency Medicine, human evaluation often centers around time-critical decision-making and triage support. Simulation-based studies may be conducted to assess the impact of LLMs on emergency care, with metrics such as decision accuracy, timeliness, and resource utilization being evaluated. Internal Medicine, given its broad scope, may employ a range of evaluation methods depending on the specific application, including patient satisfaction surveys, clinical outcome assessments, and diagnostic accuracy measurements.
Evaluation design
The evaluation of LLMs in healthcare demands a comprehensive and multifaceted approach that reflects the complexities of medical specialties and clinical tasks. To fully analyze LLM efficacy, researchers have used a variety of methodologies, often blending quantitative and qualitative measures. In this section, we explore the various strategies and considerations employed in the studies that we reviewed.
Evaluation principles and dimensions: QUEST – five principles of evaluation dimensions
We categorized the evaluation methods in the reviewed articles into 17 dimensions that are further grouped into five principles. These include Quality of Information, Understanding and Reasoning, Expression Style and Persona, Safety and Harm, and Trust and Confidence, which we name them using the acronym QUEST. Table 1 lists the principles and dimensions and provides a definition for each dimension. Most of the definitions were adapted from the meanings provided by the Merriam-Webster English Dictionary. Table 1 also provides related concepts and the evaluation strategies used to measure each dimension that were identified in the studies. Table 2 outlines examples of questions used to evaluate each dimension of LLM responses, aligned with QUEST principles.
Quality of Information examines the multi-dimensional quality of information provided by the LLM response, including their accuracy, relevance, currency, comprehensiveness, consistency, agreement, and usefulness; Understanding and Reasoning explores the ability of the LLMs in understanding the prompt and logical reasoning in its response; Expression Style and Persona measures the response style of the LLMs in terms of clarity and empathy; Safety and Harm concerns the safety dimensions of LLM response, bias, harm, self-awareness, and fabrication, falsification, or plagiarism; and, Trust and Confidence considers the trust and satisfaction the user ascribe to the LLM response.
Evaluation checklist
Among the reviewed studies, a limited number of studies did specify and report checklists they have created for the human evaluators. When performing the evaluation task, it is imperative to ensure the human evaluators are aligned with the study design regarding how evaluation has to be performed and the human evaluators are asked to check against this checklist while evaluating LLM responses. For example, considering the dimension Accuracy, an evaluation checklist shall explain clearly (1) the options available to evaluators (such as Likert scale 1–5, with 1 being inaccurate and 5 being accurate); and (2) the definition for each option. However, due to lack of reporting, it is unclear whether the reviewed studies provide adequate training and evaluation examples to align with the understanding of the recruited human evaluators.
Evaluation samples
While the above dimensions and checklists provide human evaluators the concrete qualities to evaluate, another key consideration is evaluation samples, i.e., the text responses output by the LLMs. In particular, we examined the number and the variability of samples evaluated by human evaluators in the reviewed articles.
Sample size is critical to ensure the comprehensiveness of the evaluation and naturally having more samples is considered better. However, this is limited by a combination of constraints such as the number of evaluation dimensions, the complexity of the evaluation process, the number of evaluators, and the funding. In Fig. 3, the distribution of the aggregate sample sizes in studies reviewed is shown. The majority of studies have 100 or below LLMs output for human evaluation, but we do observe one outlier study with 2995 samples by Moramarco et al.35. They designed the evaluation to be completed using Amazon Mechanical Turk (MTurk), an online crowdsourcing service. As the authors noted, MTurk has limitations in controlling the reading age and language capabilities of the annotators, necessitating a larger sample size to account for variability in the annotations. A total of 2995 sentences were evaluated in this study, with each sentence being evaluated seven times by different evaluators.
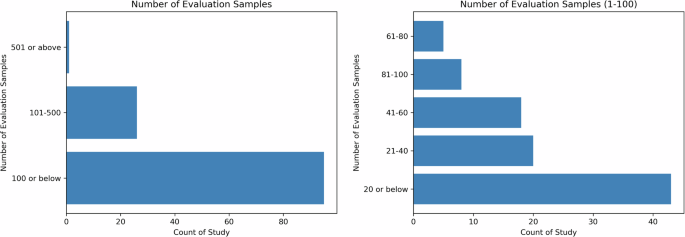
The left panel shows the distribution of sample size for all studies while the right panel depicts the distribution for studies with 1–100 sample(s).
Sample variability is important to ensure the diversity and generalizability in the human evaluation of LLMs. Depending on the availability of data and/or applications, while most questions/prompts in the reviewed studies are patient-agnostic, such as “why am I experiencing sudden blurring of vision?”, a subset of the reviewed studies incorporated patient population variability into their experiments and evaluated the quality of LLMs samples in different subgroups. Specifically, using prompt templates, these studies prompted the LLMs with different patient-specific information from sources such as patients’ clinical notes from electronic health records21,40 or clinician-prepared clinical vignettes41,42. This variability allows researchers to evaluate and compare the LLMs’ performance across different patient subpopulations, characterized by their symptoms, diagnoses, demographic information, and other factors.
Selection and recruitment of human evaluators
The recruitment of evaluators is task-dependent, as the goal of human assessment is to have evaluators representative of the actual users of LLMs for the specified task. Based on the reviewed articles, there are mainly two types of evaluators, expert and non-expert. Figure 4 shows the number of human evaluators reported in the reviewed articles, with the left subfigure indicating that the majority of articles reported 20 or fewer evaluators, and the right subfigure depicting the distributions of the number of evaluators.
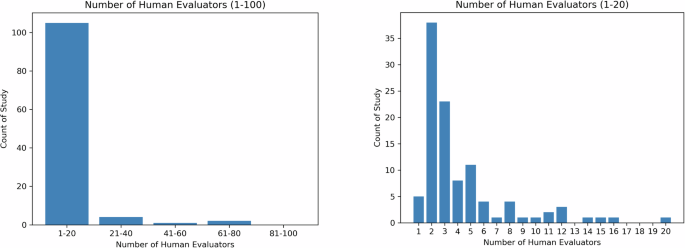
The left panel shows the distribution of the number of human evaluators for all studies while the right panel depicts the distribution for studies with 1–20 human evaluator(s).
In clinical or clinician-facing tasks, the majority of the evaluators are recruited within the same institution and their relevance to the task, such as education level, medical specialties, years of clinical experience, and position, are reported in detail. Some studies also describe the demographics of the evaluators, such as the country (e.g., Singhal et al.10). As shown in Fig. 4, a majority of studies have less than 20 evaluators, with only 3 studies recruiting more than 50 evaluators43,44,45.
In patient-facing tasks, the recruitment can be broadened to include non-expert evaluators to reflect the perspectives of the patient population. Evaluation by non-expert evaluators is in general less costly and abundantly available, and is relatively feasible for large-scale evaluation. For example, Moramarco et al.35, where the author evaluated the user-friendliness of LLM-generated response, they recruited a variety of evaluators online via crowdsourcing platform MTurk. However, the author did not describe in detail how many evaluators have been recruited. In Singhal et al.10, in addition to expert evaluation, 5 evaluators without medical background from India were recruited to evaluate the helpfulness and actionability of the LLMs’ response.
Generally, in studies with non-expert evaluation, we observe a decrease in the number of dimensions but an increase in the number of evaluators when comparing expert evaluation, showing a potential tradeoff between the depth and breadth of human evaluation.
Human evaluators and sample sizes for specific healthcare applications
We also investigated the relationship among human evaluators and sample sizes for different healthcare applications in the reviewed studies. Table 3 shows the median, mean, and standard deviation (S.D.) values of the number of evaluation samples and human evaluators for each healthcare application. Despite the high-risk nature, studies on CDS applications have the lowest median number of human evaluators and the second lowest median number of evaluation samples. A possible reason could be that CDS requires more qualified human evaluators who are more difficult and expensive to recruit. Patient-facing applications (e.g., patient education and patient-provider question answering), on the other hand, have a larger number of both evaluation sample size and human evaluators. It is notable that the variability in sample sizes across the reviewed studies is very high.
Figure 5 exhibits an inverse relationship between evaluation sample size and the number of human evaluators as reported in the reviewed studies. This exhibits a potential challenge in recruiting a large number of evaluators who have the capacity and/or capability to evaluate a high quantity of samples.
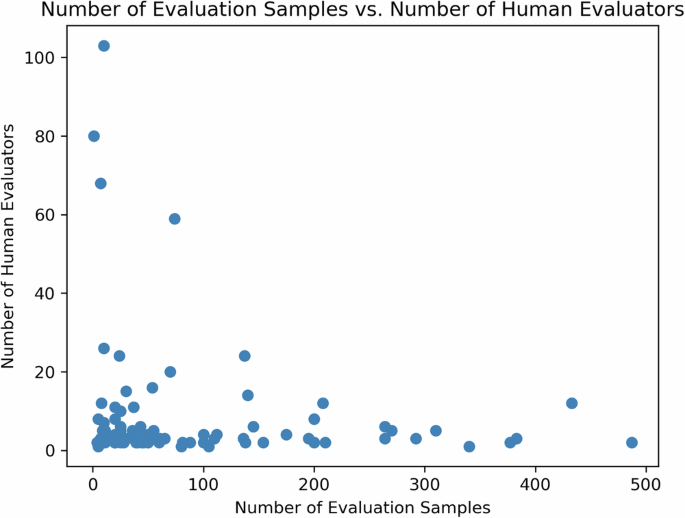
An inverse relationship is found between evaluation sample size and the number of human evaluators as reported in the reviewed studies. This exhibits a potential challenge in recruiting a large number of evaluators who have the capacity and/or capability to evaluate a high quantity of samples.
Evaluation tools
The evaluation of LLMs in healthcare relies on a range of evaluation tools to assess their responses and overall performance. A key aspect of this evaluation is the assessment of narrative coherence and logical reasoning, which often involves binary variables to determine how well the model incorporate internal and external information40. Additionally, the evaluation also extends to identifying errors or limitations in the model’s responses, categorized into logical, informational, and statistical errors. Analyzing these errors provides valuable insights into areas where the LLMs may need improvement or further training.
Likert scale is another widely adopted tool used in human evaluations of LLMs, ranging from simple binary scales to more nuanced 5-point or 7-point scales40. Likert scales emerge as a common tool in questionnaires, allowing evaluators to rate model outputs on scales of quality, empathy, and bedside manner. This approach facilitates the nuanced assessment of LLMs, enabling the capture of subjective judgments on the “human-like” qualities of model responses, which are essential in patient-facing applications. These scales allow participants to express degrees of agreement or satisfaction with LLM outputs, providing a quantitative measure that can be easily analyzed while capturing subtleties in perception and experience. For example, 4-point Likert-like scales allow evaluators to differentiate between completely accurate and partially accurate answers, offering a more detailed understanding of the LLM’s performance46. Additionally, 5-point Likert scales have been utilized to capture the perceptions of evaluators regarding the quality of simplified medical reports generated by LLMs47. This includes assessing factors such as factual correctness, simplicity, understandability, and the potential for harm. By employing these evaluation tools, researchers can quantitatively analyze the performance of LLMs and conduct downstream statistical analysis while also capturing the subtleties inherent in human perception and experience.
Comparative analysis
The reviewed studies often employ comparative analyses, comparing LLM outputs against human-generated responses, other LLM-generated outputs, or established clinical guidelines. This direct comparison allows for a quantitative and qualitative assessment of the evaluation dimensions such as accuracy, relevance, adherence to medical standards, and more, as exhibited by the LLMs. The distribution of comparison analyses used in the studies is provided in Supplementary Fig. 2. By treating human responses or guidelines as benchmarks, researchers can identify areas where LLMs excel or require improvement. Notably, 20% (n = 29) of the studies incorporated a unique approach by comparing LLM-generated outputs with those of other LLMs. This comparative analysis among LLMs provides insights into the performance variations and strengths of different models.
For instance, Agarwal et al. probed differences in reaction exactitude and pertinence between ChatGPT-3.5 and Claude-2 by taking advantage of repeated measures Analysis of variance (ANOVA), centering on diversified clinical query categories48. Wilhelm et al. weighed the performance of four influential LLMs – Claude-1, GPT-3.5, Command-Xlarge-nightly, and Bloomz- by implementing ANOVA to investigate statistical differences in therapy guidance produced by every model49.
Gilson et al.50 executed a thorough examination of outputs from ChatGPT across situations extracted from USMLE50. Ayers et al.3 compared responses from ChatGPT to those supplied by physicians on Reddit’s “Ask Doctors” threads, utilizing chi-square tests to establish whether notable differences existed concerning advice quality and relevance. Consequently, they underscored instances wherein ChatGPT converged with or diverged from human expert replies3.
Some of the reviewed studies also consider the importance of testing LLMs in both controlled and real-world scenarios. Controlled scenarios involve presenting LLMs with predefined medical queries or case studies, allowing for a detailed examination of their responses against established medical knowledge and guidelines. In contrast, real-world scenarios test the practical utility and integration of LLMs into live clinical environments, providing insights into their effectiveness within actual healthcare workflows.
Blinded vs. unblinded
A prominent feature of human evaluations is the use of blind assessments, where evaluators are unaware of whether the responses are generated by LLMs or humans. Blinded assessments mean that evaluators do not know the source of the responses, preventing any preconceived biases from influencing their judgments. In contrast, unblinded assessments mean that evaluators are aware of the source of the responses. Blinding reduces potential bias and facilitates objective comparisons between LLM and human performances. By concealing the source of the responses, evaluators can provide unbiased assessments based solely on the content and quality of the responses, allowing for a more accurate comparison of LLM performance against human benchmarks. This approach is particularly valuable when assessing the quality and relevance of LLM outputs in direct relation to human expertise.
In the reviewed studies, a mixed approach to blinding was observed. Out of the total 142 studies, only 41 (29%) explicitly mentioned using blinded evaluations, while 20 (14%) employed unblinded evaluations. Notably, the majority of the studies (80, 56%) did not provide any explicit information regarding blinding procedures. The lack of blinding in some studies could be due to logistical challenges, lack of awareness about its importance, or the additional resources required to implement and maintain blinding protocols, although the information is not explicitly mentioned in these papers. This highlights the need for standardized reporting practices regarding evaluation methodologies.
Among the studies employing blind assessments, the approaches also vary significantly. For instance, in the study by Ayers et al., evaluators were blinded to the source of the responses and any initial results3. In contrast, Dennstadt et al. utilized blinded evaluations specifically for multiple-choice questions, determining the proportion of correct answers provided by the LLM51. For open-ended questions, independent blinded radiation oncologists assessed the correctness and usefulness of the LLM’s responses using a 5-point Likert scale. To strengthen the reliability and validity of human evaluation studies and enable more robust assessments of LLM performance, we recommend that future studies should consistently implement and report blinding procedures in their evaluation methodologies. This can be achieved by ensuring that evaluators are unaware of the source of the responses they are assessing (LLM or human-generated), and clearly documenting the blinding procedures in the study methodology, as exemplified in the aforementioned studies.
Statistical analysis
After collecting the ratings from evaluators, various statistical techniques are employed in the literature for analyzing the evaluation results. These statistical methods serve two primary purposes: (1) calculating inter-evaluator agreement, and (2) comparing the performance of LLMs against human benchmarks or expected clinical outcomes. Table 4 shows an overview of the top 11 statistical analysis conducted in the reviewed studies. To help researchers decide which statistical analysis method to choose, we provide a decision tree in Fig. 6.
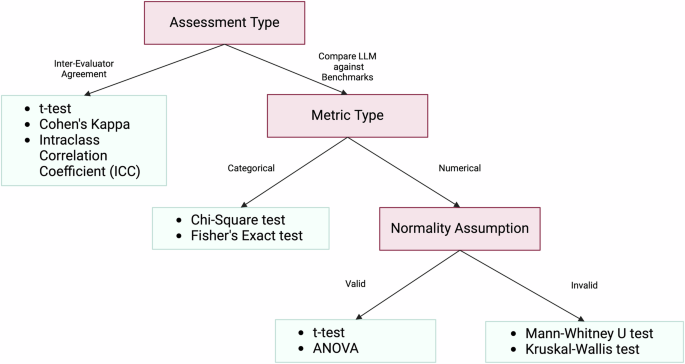
The choice of specific statistical tests is based on the type of data and the evaluation objectives within the context of each study. Parametric tests such as t-tests and ANOVA are chosen when the data are normally distributed and the goal is to compare means between groups, ensuring that the means of different groups are statistically analyzed to identify significant differences. Non-parametric tests like the Mann–Whitney U test and Kruskal–Wallis test are used when the data do not meet normality assumptions, providing robust alternatives for comparing medians or distributions between groups for ordinal or non-normally distributed data. Chi-Square and Fisher’s Exact tests are suitable for analyzing categorical data and assessing associations or goodness-of-fit between observed and expected frequencies, making them appropriate for evaluating the fit between LLM-generated medical evidence and clinical guidelines. Measures like Cohen’s Kappa and ICC are utilized to assess inter-rater reliability, ensuring that the agreement between evaluators is not due to chance and enhancing the reliability of the evaluation results.
Ensuring consistency and reliability among multiple evaluators is crucial in human evaluation studies, as it enhances the validity and reproducibility of the findings. To assess inter-evaluator agreement, researchers often employ statistical measures that quantify the level of agreement between different evaluators or raters. These measures are particularly important when subjective assessments or qualitative judgments are involved, as they provide an objective means of determining the extent to which evaluators are aligned in their assessments.
Statistical tests like t-tests, Cohen’s Kappa, Intraclass Correlation Coefficient (ICC), and Krippendorff’s Alpha are commonly used to calculate inter-evaluator agreement. These tests take into account the possibility of agreement occurring by chance and provide a standardized metric for quantifying the level of agreement between evaluators. Schmidt et al. determined statistical significance in radiologic reporting using basic p-values39, while studies like Sorin et al. and Elyoseph et al.52 used ICC to assess rater agreement and diagnostic capabilities. Sallam et al.53 and Varshney et al.54 have used a combination of t-tests and Cohen’s kappa to identify potential sources of disagreement, such as ambiguity in the evaluation guidelines or differences in interpretations.
Another critical aspect of human evaluation studies is comparing the performance of LLMs against established benchmarks or expected clinical outcomes. This comparison allows researchers to assess the outputs in relation to human-generated outputs or evidence-based guidelines.
Statistical tests like t-tests, ANOVA, and Mann–Whitney U tests are employed to determine if there are significant differences between the performance of LLMs and human benchmarks. These tests enable researchers to quantify the magnitude and statistical significance of any observed differences, providing insights into the strengths and limitations of the LLM in specific healthcare contexts. Wilhelm et al. applied ANOVA and pairwise t-tests for therapy recommendation differences49; and Tang et al. utilized the Mann–Whitney U test for medical evidence retrieval tasks under non-normal distribution conditions34. Liu et al. combined the -WhitneManny Wilcoxon test and the Kruskal–Wallis test for evaluating the reviewer ratings for the AI-generated suggestions5. Bazzari and Bazzari chose the Mann–Whitney U test to compare LLM effectiveness in telepharmacy against traditional methods when faced with non-normal sample distributions46. Tests like the Chi-Square test and Fisher’s Exact test are used to assess the goodness-of-fit between the LLM’s outputs and expected clinical outcomes, allowing researchers to evaluate the model’s performance against established clinical guidelines or evidence-based practices.
The choice of specific statistical tests is based on the type of data and the evaluation objectives within the context of each study. Parametric tests such as t-tests and ANOVA are chosen when the data are normally distributed and the goal is to compare means between groups, ensuring that the means of different groups are statistically analyzed to identify significant differences. Non-parametric tests like the Mann–Whitney U test and Kruskal–Wallis test are used when the data do not meet normality assumptions, providing robust alternatives for comparing medians or distributions between groups for ordinal or non-normally distributed data. Chi-Square and Fisher’s Exact tests are suitable for analyzing categorical data and assessing associations or goodness-of-fit between observed and expected frequencies, making them appropriate for evaluating the fit between LLM-generated medical evidence and clinical guidelines. Measures like Cohen’s Kappa and ICC are utilized to assess inter-rater reliability, ensuring that the agreement between evaluators is not due to chance and enhancing the reliability of the evaluation results.
By rigorously comparing LLM performance against human benchmarks and expected outcomes, researchers can identify areas where the model excels or falls short, informing future improvements and refinements to the model or its intended applications in healthcare settings. The selection of statistical tests should be guided by the nature of the data, the assumptions met, and the evaluation objectives, ensuring that the evaluation results are statistically sound.
Specialized frameworks
In addition to questionnaire-based assessments, studies have also utilized established evaluation frameworks and metrics. Frameworks like SERVQUAL, PEMAT-P, and SOLO structure have been applied to structure the assessment of LLM performance comprehensively (Table 5). Various metrics, including accuracy rates, user satisfaction indices, and ethical compliance rates, have been employed to quantify and compare the performance of LLMs against defined standards.
The SERVQUAL model, a five-dimension framework, was employed by Choi et al. to assess the service quality of ChatGPT in providing medical information to patients with kidney cancer, with responses from urologists and urological oncologists surveyed using this framework55. Studies like Choi et al.55 shed light on the potential and limitations of LLMs in direct patient interactions and learning gains. They investigated ChatGPT’s ability to provide accessible medical information to patients with kidney cancer, using the SERVQUAL model to assess service quality.
In addition to generic evaluation scales, some studies employ specialized questionnaires designed to assess specific aspects of LLM performance, such as factual consistency, medical harmfulness, and coherence. The DISCERN instrument, a validated tool for judging the quality of written consumer health information, has been adapted in several studies to evaluate the trustworthiness and quality of information provided by LLMs. However, these specialized frameworks do not cover all metrics and fail to provide a comprehensive method of evaluation across all QUEST dimensions.