
Text mining
Text mining, which involves extracting useful information and knowledge from large volumes of textual data, employs NLP and machine learning tools and techniques for information retrieval to process and analyse unstructured text15,26,28. The principal purpose of text mining is to capture and analyse all possible meanings embedded in the text15,26,28. This approach can uncover hidden patterns and trends in a variety of unstructured data sources, including academic literature, patents, news articles, social media posts, Twitter feeds and video transcripts. By employing text mining on scientific papers and patents to identify early indicators of technology trends, promising technologies within specific domains can be identified, supporting technology road mapping and life cycle analysis14,23. Traditional topic models such as Latent Dirichlet Allocation (LDA) may generate imprecise or scattered topics due to the subjective judgment of researchers when dealing with highly heterogeneous data sets18,37.
The bag-of-words model
Under the topic of AI and healthcare, quantitative methods for text data play a vital role in enhancing the explanatory and predictive power of models. By converting text into quantitative indicators, high-quality information can be extracted as new features or variables to explore and solve problems that were previously impossible to quantify and analyse in more depth. In each document, unique words are treated as individual features, and these word occurrences can be used for documents comparison, measuring similarities of documents, topic modelling and text mining38. If there are \(K\) unique words that are not repeated in \(M\) documents, an \(M*K\) matrix is formed38. And the specific calculation equation is
$${f}_{i,j}={\sum }_{k}^{{m}_{i,j}}{m}_{k,j}$$
The bag-of-words model, while successful in information retrieval tasks, has notable limitations39. It fails to capture context or word order, treats words as independent entities ignoring their combined associations, and can struggle with overly complex models due to an excessive number of features, which may dilute important terms and complicate computations39.
Bidirectional encoder representations from transformers (BERT)
To address the limitations of traditional, overly subjective analysis methods, deep learning models have gradually become a potential analysis method for technology forecasting27,28,31,32,33. In 2018, BERT was first introduced by Google researchers as a new language representation model35. It is the first transformer model to truly take advantage of bidirectional training. This enables the model to better understand the language context. The core innovation of BERT is its use of a large-scale corpus for pre-training, followed by fine-tuning for specific tasks to improve performance across various NLP applications. Unlike traditional topic modelling techniques, such as LDA, which assumes a fixed distribution of topics across the documents, BERT’s deep learning-based approach allows for a more nuanced understanding of the text by leveraging its bidirectional attention mechanism. This helps capture intricate dependencies between words in a sentence and across documents. Additionally, compared to t-SNE or PCA, which are primarily used for dimensionality reduction and visualization, BERT excels in extracting meaningful representations from large datasets without requiring explicit topic hypothesis40,41. The pre-training process of BERT includes the learning tasks of masked language model (MLM) and next sentence prediction (NSP)33,36. During the training process, MLM randomly masks certain words in the input sentence and replaces the original words with special mask labels29. Each time a sequence is sampled, MLM randomly masks a certain proportion of words and lets the model predict each masked word-piece label independently25,29,29,35. Essentially, a deep learning task is formulated from a large unlabelled corpus of images and the convolutional neural network predicts a masked area of the image for most pretext tasks or predicts the correct angle by which the image is rotated42. NSP is a supervised learning task that takes a pair of sentences as input29. BERT predicts whether the given two sentences are coherent. This task is achieved by labelling the input sentence pairs (yes or no). The model then learns the relationships between sentences29. Supervised learning involves a training process where both the observed data and its corresponding ground truth labels (sometimes referred to as “targets”) are essential for training the model43. For instance, in breast X-ray examinations, cancerous areas are precisely outlined (as labels), enabling the algorithm to “learn” the characteristics of malignant tumours from these annotated markers6,31. In contrast, BERT may learn and complete pre-training through unsupervised learning, where the training data does not have diagnostic or normal/abnormal labels43.
BERT, as a newly introduced model in the field of NLP, can reveal complex patterns hidden in text data based on the transformer model, which greatly improves the accuracy of information extraction and text analysis4,35,36. Papers, patents, research reports and other forms of text data have become key resources for obtaining the latest scientific and technological progress and market trends. It can be considered an important indicator for identifying technological paths and market trends. Due to the complexity and rapid development of technology, analysing only the technology opportunities identified from a single data source may be one-sided. This research aims to use the Colab tool to perform BERT analysis to identify the gap between patents and academic papers, thereby predicting changes in technology development trends.
Data collection and data analysis
To ensure a rigorous and transparent data collection process, this research adheres to PRISMA guidelines, systematically selecting the Web of Science (WOS) for scientific literature and the Derwent Innovations Index (DII) for patent data. WOS was chosen as the source of scientific papers related to AI diagnosis because it includes top interdisciplinary journals and conference papers, and the peer-reviewed, high-quality research content ensures the authority of the research14. This is very valuable for tracking the research dynamics of AI in the field of healthcare diagnosis and identifying key research. At the same time, DII is selected as the source of patent data mainly owing to its detailed global patent information, including invention descriptions, legal status and patent citations44. In WOS, this research conducted a comprehensive search using keywords such as “artificial intelligence diagnosis” and “healthcare”, screening out 1587 papers. In DII, a patent search was conducted through the combination of keywords “artificial intelligence diagnosis”, “AI diagnosis”, “artificial intelligence”, “diagnosis” and “healthcare”, yielding 1314 qualifying patents. These data collection activities concluded on June 16, 2023. According to the data collected by WOS and DII document libraries, the unstructured datasets of AI in diagnosis are relatively concentrated from 2018 to 2022. Specifically, there was little relevant text data before 2018, and there was an 18-month intellectual property protection period for the data. Following PRISMA, this study conducted a structured screening process: identification, duplicate removal, full-text review, and final inclusion. To enhance dataset construction, we applied the BERT model to integrate literature and patent data, ensuring a systematic, reproducible, and comprehensive analysis of AI’s role in healthcare diagnostics.
After data collection is complete, further data preprocessing is usually performed to improve data quality and validity. This preprocessing process covers key steps such as data cleaning, standardisation, entity recognition and word segmentation. Subsequently, BERT is trained on the data to further analyse AI in healthcare. This begins with model parameter tuning, which involves setting the appropriate learning rate, batch size and number of training epochs to optimise training results. Using the pandas package, the code preprocesses a DataFrame by extracting and formatting dates, cleaning splitting text columns (‘TI’, ‘AB’, ‘PI’) and removing rows with missing or duplicate values. It then filters the data by a specified date range, retains relevant columns, and outputs the cleaned DataFrame. Selecting an appropriate validation set is crucial, as it helps monitor model training progress and prevent overfitting. The next step involves model optimisation. The back propagation algorithm is used to continuously adjust the model weights to ensure that the model can effectively process medical text data. Finally, the model is pre-trained on a large-scale corpus to learn the basic characteristics of language, and then fine-tuned for specific medical tasks to improve task performance and accuracy. In this research, a pre-trained BERT model is used and fine-tuned using the MLM and NSP training tasks. Hyperparameters such as learning rate, batch size, and the number of training epochs are adjusted during fine-tuning. The code uses UMAP for dimensionality reduction, setting parameters such as n_neighbors, n_components, min_dist and metric. The code implements the K-Means clustering algorithm to group the text embeddings into 50 clusters.
In the current case analysis, this research applies BERTopic to deeply explore the latest trends of AI in the field of healthcare. The flow chart is as follows. This process takes the embedding of the document as the starting point and uses BERT, a bidirectional encoder representation technology, to convert the text into a dense vector form45. Using BERT or similar techniques, text data is encoded into vectors containing rich semantic information. This transformation not only captures the complex connections between words but also preserves their meaning in specific contexts. BERTopic uses Sentence Transformers to perform this step, and the specific operation steps will be implemented through Colab’s code, as shown in Fig. 245.
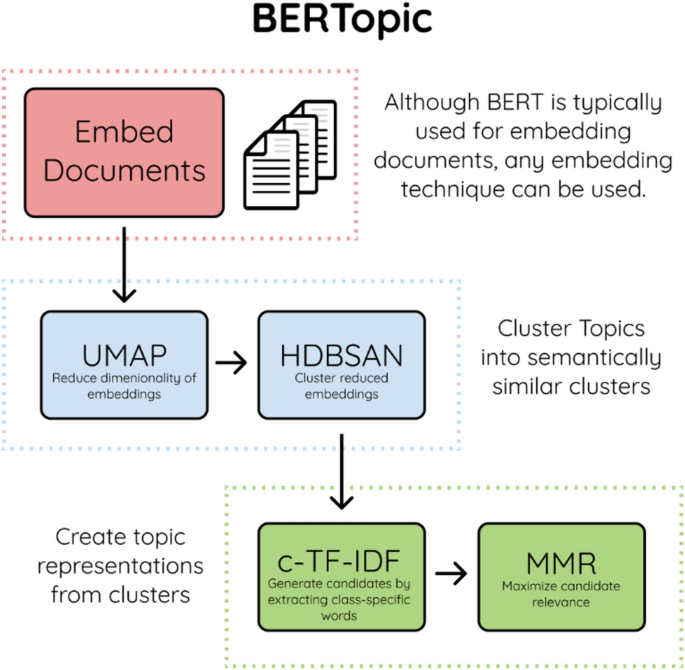
The research process of study29.
Document embedding converts text into vectors for machine learning models45,46,47. This study then applies the uniform manifold approximation and projection (UMAP) algorithm to reduce vector dimensionality, while preserving the original data structure48. UMAP was chosen over other dimensionality reduction techniques (such as PCA and t-SNE) mainly because UMAP is better at preserving local and global structures when dealing with high-dimensional data, especially for complex relationships in text data45,48,49,50,51. UMAP efficiently compresses high-dimensional data into lower dimensions by constructing a weighted graph, maintaining local and global structures 45,48,49,50,51. This reduction step enhances computational efficiency and simplifies data visualisation for clustering algorithms.
$$w\left( {x_{i} ,{ }x_{j} } \right) = exp\left( {\frac{{ – max\left( {0,{ }d\left( {x_{i} ,{ }x_{j} } \right) – p_{i} } \right)}}{{\sigma_{i} }}} \right),$$
where \(w\left({x}_{i}, {x}_{j}\right)\) is the weight of the edge between points \({x}_{i}\) and \({x}_{j}\), indicating the similarity between them; \(d\left({x}_{i}, {x}_{j}\right)\) represents the distance between points \({x}_{i}\) and \({x}_{j}\); \({p}_{i}\) is the local scale parameter of point \({x}_{i}\), usually representing the distance between the kth nearest neighbour and point \({x}_{i}\), to ensure that each point is connected to at least one other point; \({\sigma }_{i}\) is a length scale parameter used to adjust the influence of distance; \(max\left(0, d\left({x}_{i}, {x}_{j}\right)-{p}_{i}\right)\) is usually used to ensure that only part of the distance beyond the local scale \({p}_{i}\) is calculated, thereby limiting the influence of farther points on the weight50.
After dimensionality reduction, the hierarchical density-based spatial clustering of applications with noise (HDBSCAN) algorithm is employed for clustering, identifying natural clusters and handling noisy data without presetting the number of clusters52. HDBSCAN calculates the core distance to the kth nearest neighbour and uses mutual reachable distance to differentiate dense and sparse regions, improving the accuracy of clustering53. While HDBSCAN identified approximately 10% of the data points as outliers, based on expert judgment, this research determined that in the context of our research dataset, patent data should not be considered outliers. Given this, K-means is a more suitable algorithm for this research. It was used to identify the critical research domains and future research directions54. The next step involves creating topic representations using class-based term frequency–inverse document frequency (C-TF–IDF). It identifies keywords for each cluster by calculating their term frequency and inverse document frequency, enhancing topic clarity46. Maximum marginal relevance is then applied to refine keywords, balancing relevance and novelty for better topic distinction46. The equations are as follows.
\({core}_{k}^{x}=dx, {N}^{k}x\)53.
\({d}_{mreach-k}a, b={maxcore}_{k}a, {core}_{k}b, da, b.\)53.
\({W}_{t, d}=t{f}_{t, d}\cdot \text{log}\left(\frac{N}{d{f}_{t}}\right)\)29.
It is calculated by dividing the number of documents in the corpus \(N\) by the total number of documents containing \(t\), and then taking the logarithm; where \({W}_{t, d}\) refers to the weight of term \(t\) in document \(d\); \(t{f}_{t, d}\) is the term frequency of term \(t\) in document \(d\), that is, the number of times term \(t\) appears in document \(d\); \(N\) is the total number of documents in the document collection; \(d{f}_{t}\) is the number of documents containing the term \(t\), that is, the number of documents in which term \(t\) appears; \(\text{log}\left(\frac{N}{d{f}_{t}}\right)\) is the calculation method of inverse document frequency, and the higher the value, the less common term \(t\) is in the entire document collection, and therefore the more important it is within a particular document46. This step not only identifies the core concepts of each topic but also provides an intuitive vocabulary list for understanding the uniqueness of each cluster. Words in a topic may be like each other and may be redundant for the explanation of the topic. In theory, this problem can be solved by applying the maximum marginal relevance to the first n words in topic46. This algorithm selects the most representative key words by balancing their relevance and novelty.